23 de Marzo 2022
Abstract:
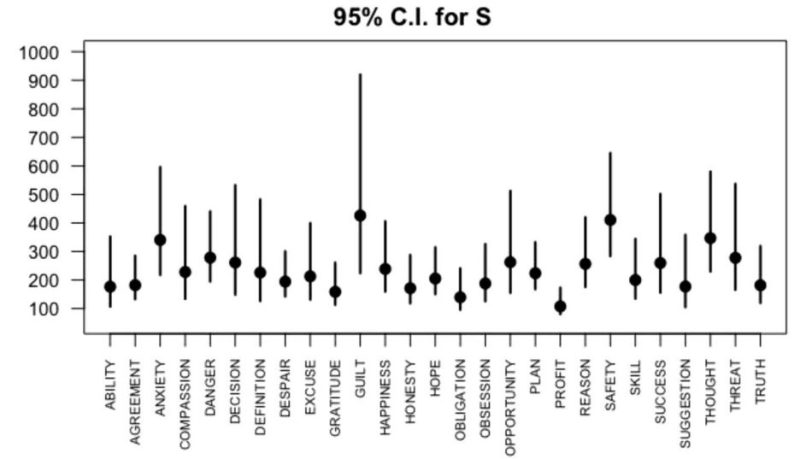
In conceptual properties norming studies (CPNs), participants list properties that describe a set of concepts. From CPNs, many different parameters are calculated, such as semantic richness. A generally overlooked issue is that those values are only point estimates of the true unknown population parameters. In the present work, we present an R package that allows us to treat those values as population parameter estimates. Relatedly, a general practice in CPNs is using an equal number of participants who list properties for each concept (i.e., standardizing sample size). As we illustrate through examples, this procedure has negative effects on data’s statistical analyses. Here, we argue that a better method is to standardize coverage (i.e., the proportion of sampled properties to the total number of properties that describe a concept), such that a similar coverage is achieved across concepts. When standardizing coverage rather than sample size, it is more likely that the set of concepts in a CPN all exhibit a similar representativeness. Moreover, by computing coverage the researcher can decide whether the CPN reached a sufficiently high coverage, so that its results might be generalizable to other studies. The R package we make available in the current work allows one to compute coverage and to estimate the necessary number of participants to reach a target coverage. We show this sampling procedure by using the R package on real and simulated CPN data.